Le séquençage Nanopore a été découvert en 19951 et a pour objectif de séquencer des échantillons d’ADN, c’est-à-dire de déterminer l’ordre dans lequel se trouvent les 4 bases Adénine (A), Cytosine (C), Thymine (T) et Guanine (G) des nucléotides sur le brin d’ADN.
Principe
Le principe du séquençage par Nanopore est de déterminer la séquence de la molécule d’ADN par l’utilisation de nanopores (pores avec un diamètre de l’ordre d’un nanomètre).
Les nanopores peuvent être :
- d’origine biologique en utilisant des protéines transmembranaires telles que les porines,
- d’origine synthétique construits à partir de résidus de silicium2 ou de graphène3. Dans le cas du silicium, un trou de quelques nanomètres est partiellement comblé avec des couches d’ions déposées à l’aide de méthodes de sculpture par faisceau d'ions2. Le diamètre du pore est alors de l’ordre de 1 nm.
Lorsqu’un nanopore est placé dans un milieu conducteur et soumis à un voltage, il est traversé par un courant électrique issu de la conduction d’ions. Ce courant est mesurable et dépend de :
- la taille et la forme du nanopore,
- la nature et concentration des particules traversant ou passant à proximité du nanopore.
Le courant est ainsi modifié de manière caractéristique lorsque le pore est traversé ou obstrué par un nucléotide contenant les bases A, C, T ou G. En faisant passer un brin d’ADN par le nanopore, il est donc possible de déterminer la séquence de la molécule4.
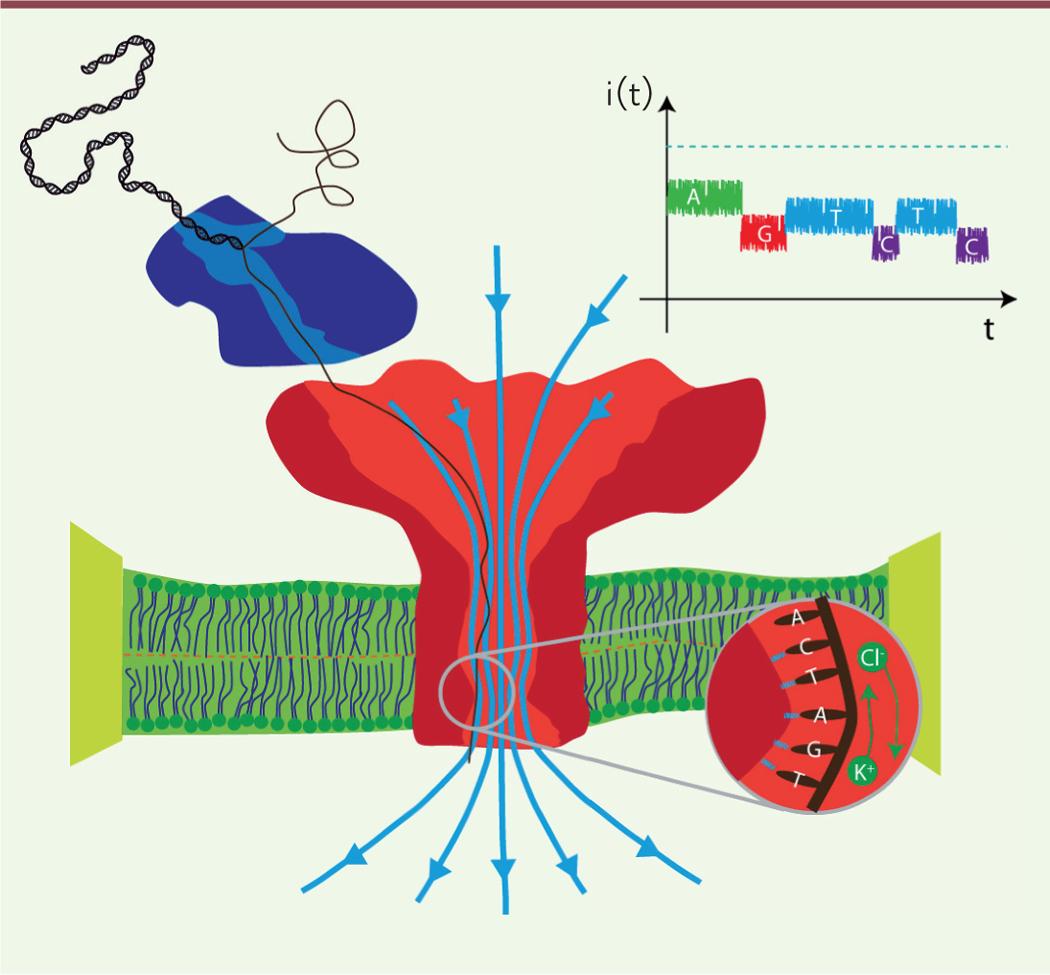
L’ADN étant double brin, il ne peut passer dans le nanopore que si l’hélice est ouverte. Pour cela, des enzymes comme l’hélicase ou l’ADN polymérase génétiquement modifiée sont utilisées pour se complexer avec le pore et ouvrir l’hélice d’ADN directement en direction du pore (Figure 1)5.
Figure 1 : Principe du séquençage par Nanopore biologique 5
L’hélice d’ADN est ouverte par une enzyme (en bleu), et le brin simple d’ADN peut ainsi passer à travers du nanopore (en rouge) qui se trouve au sein d’une membrane (en vert). Le courant ionique (flèches bleues) favorise le passage de l’ADN à travers le pore, entraînant ainsi un changement de vitesse de passage des ions, selon le nucléotide qui se trouve dans le pore (encerclé en bas à droite). Le graphique en haut représente l’identification des nucléotides, par rapport au courant mesuré, le pointillé bleu représentant le courant à vide.
Mode opératoire
Le séquençage par nanopore est une technique commercialisée par Oxford Nanopore Technologies, une entreprise qui a depuis lancé son premier dispositif portable de séquençage par nanopores. Afin de pouvoir effectuer ce séquençage, des kits de réactifs sont commercialisés avec la machine.
Pour charger le séquenceur, il faut premièrement amorcer la cellule d’écoulement. Pour cela, 800 µl de tampon d'amorçage sont introduits dans la cellule via le pore d'amorçage, en évitant l'introduction de bulles d'air. Après avoir attendu 5 min, le couvercle du port d'échantillonnage SpotON est soulevé et le reste du tampon d’amorçage, soit 200 µl, est introduit dans la cellule d’écoulement via le pore d’amorçage6.
L’échantillon d’ADN à séquencer est mélangé doucement par pipetage avant le chargement. Puis, 75 μl d’échantillon sont introduits goutte à goutte à la cellule d’écoulement via le pore d'échantillonnage SpotON préalablement ouvert6.
Le séquençage est alors réalisé, les résultats pouvant être lu en direct sur l’ordinateur.
Le principe de fonctionnement du séquenceur nanopore est résumé dans la Figure 2.
Figure 2 : Principe de fonctionnement du séquenceur MinION de l’entreprise Oxford Nanopore Technologies7
Présentation des résultats
Le séquenceur donne le résultat sous forme d’une variation de courant déjà analysée. La séquence peut ainsi être directement lue (Figure 3).
Figure 3 : Exemple de résultat de séquençage par nanopore8
À chaque nucléotide est associé un changement d’intensité caractéristique traduisant l’encombrement du canal lors de son passage (Figure 2). Pour déterminer de quelle base il s’agit, il suffit de comparer le niveau d’intensité électrique lors de son passage dans le canal à l’intensité électrique mesurée à vide. Ainsi :
- la base A correspond à un courant d'environ 2 picoampères (pA).
- la base G correspond à un courant d'environ 4 pA.
- la base C correspond à un courant d'environ 6 pA.
- la base T correspond à un courant d'environ 7 pA.
Interprétation des résultats
L’interprétation des résultats dépend de ce que le chercheur veut faire. Il est possible de comparer ces résultats à des logiciels de bio-informatique, et ainsi d’identifier des patterns relatifs à certains gènes ou sites de fixation. Il est également possible de mettre en évidence des mutations entraînant par exemple une maladie génétique.
Intérêts et limites
Le séquençage nanopores a de nombreux avantages :
- Il ne nécessite pas d’amplification préalable de l’ADN et permet donc d'éliminer toute erreur introduite au cours du processus d'amplification et de simplifier les manipulations.
- Il permet le séquençage d’échantillons atteignant des longueurs allant jusqu’à 1Mb. Ainsi, il est possible de séquencer un génome complet grâce à cette méthode.
- Il fait partie des méthodes de séquençage les plus rapides (entre 1 min et 72 h). Ce paramètre dépend de la taille et de la nature de la molécule à séquencer, mais aussi du type d’appareil utilisé9.
- Les séquenceurs ONT sont moins chers, portables et de taille nettement plus réduite, par rapport aux plateformes de séquençage de deuxième génération, ce qui permet par exemple un séquençage directement sur le terrain10.
Une des principales limites de cette technique est un taux d’erreur relativement élevé (2-15 %) par rapport à celui observé avec les technologies à lecture courte9. Afin de lutter contre ceci, les nanopores sont constamment améliorés pour favoriser, par exemple, un passage plus lent des nucléotides à travers le pore. De plus, les pores synthétiques sont de plus en plus utilisés, et de nouvelles méthodes sont élaborées afin de compenser cette faiblesse. Le séquençage nanopore par fluorescence5, par exemple, qui couple les nucléotides à des fluorescents, augmentant ainsi la précision d’identification des nucléotides, est en plein développement.
Une autre limite de la méthode est la nécessité de disposer de quantités relativement importantes de matériel génétique9.
Références bibliographiques
[1] Kasianowicz JJ, Brandin E, Branton D et Deamer DW. (1996). Characterization of individual polynucleotide molecules using a membrane channel. Proceedings of the National Academy of Sciences., 93 (24), p. 13770–3.
[2] Cai Q, Ledden B, Krueger E, Golovchenko JA, et Li J. (2006). Nanopore sculpting with noble gas ions. J Appl Phys. 100(2), p. 24914-249146.
[3] Garaj S, Hubbard W, Reina A, Kong J, Branton D, et Golovchenko J. A. (2010). Graphene as a subnanometre trans-electrode membrane. Nature, 467(7312), p. 190–193.
[4] Raza S & Ameen A. (2017). Nano pore Sequencing Technology: A Review. International Journal of Advances in Scientific Research. 3 (8), 90.
[5] Montel F. (2018) Séquençage de l’ADN par nanopores - Résultats et perspectives. Med Sci. 34 (2). 161-165
[7] Wang Y, Zhao Y, Bollas A, Wang Y et Fai Au K (2021) Nanopore sequencing technology, bioinformatics and applications. Nat Biotechnol. 39, 1348–1365
[8] Fuller C, Kumar S, Porel M, Chien M, Bibillo A, Stranges P, Dorwart M, Tao C, Li Z, Guo W, Shi S, Korenblum D, Trans A, Aguirre A, Liu E, Harada E, Pollard J, Bhat A, Cech C, et Ju J. (2016). Real-time single-molecule electronic DNA sequencing by synthesis using polymer-tagged nucleotides on a nanopore array. Proceedings of the National Academy of Sciences. 113 (19), 201601782.
[9] Taishan H, Nilesh C, Dimitri M, et Anh D. (2021) Next-generation sequencing technologies: An overview. Human Immunology. 82(11), 801-811
[10] Quick J, Loman NJ, Duraffour S, Simpson JT, Severi E, Cowley L, Bore JA, Koundouno R, Dudas G, Mikhail A, Ouédraogo N, Afrough B, Bah A, Baum JH, Becker-Ziaja B, Boettcher JP, Cabeza-Cabrerizo M, Camino-Sanchez A, Carter LL, Doerrbecker J, Enkirch T, Dorival IGG, Hetzelt N, Hinzmann J, Holm T, Kafetzopoulou LE, Koropogui M, Kosgey A, Kuisma E, Logue CH, Mazzarelli A, Meisel S, Mertens M, Michel J, Ngabo D, Nitzsche K, Pallash E, Patrono LV, Portmann J, Repits JG, Rickett NY, Sachse A, Singethan K, Vitoriano I, Yemanaberhan RL, Zekeng EG, Trina R, Bello A, Sall AA, Faye O, Faye O, Magassouba N, Williams CV, Amburgey V, Winona L, Davis E, Gerlach J, Washington F, Monteil V, Jourdain M, Bererd M, Camara A, Somlare H, Camara A, Gerard M, Bado G, Baillet B, Delaune D, Nebie KY, Diarra A, Savane Y, Pallawo RB, Gutierrez GJ, Milhano N, Roger I, Williams CJ, Yattara F, Lewandowski K, Taylor J, Rachwal P, Turner D, Pollakis G, Hiscox JA, Matthews DA, O'Shea MK, Johnston AM, Wilson D, Hutley E, Smit E, Di Caro A, Woelfel R, Stoecker K, Fleischmann E, Gabriel M, Weller SA, Koivogui L, Diallo B, Keita S, Rambaut A, Formenty P, Gunther S et Carroll MW.(2016) Real-time, portable genome sequencing for Ebola surveillance. Nature. 530, 228–232